REAnalyst
Multi-agent real estate investment analysis platform that produces comprehensive buy/finance/pass recommendations through specialized LLM agents.
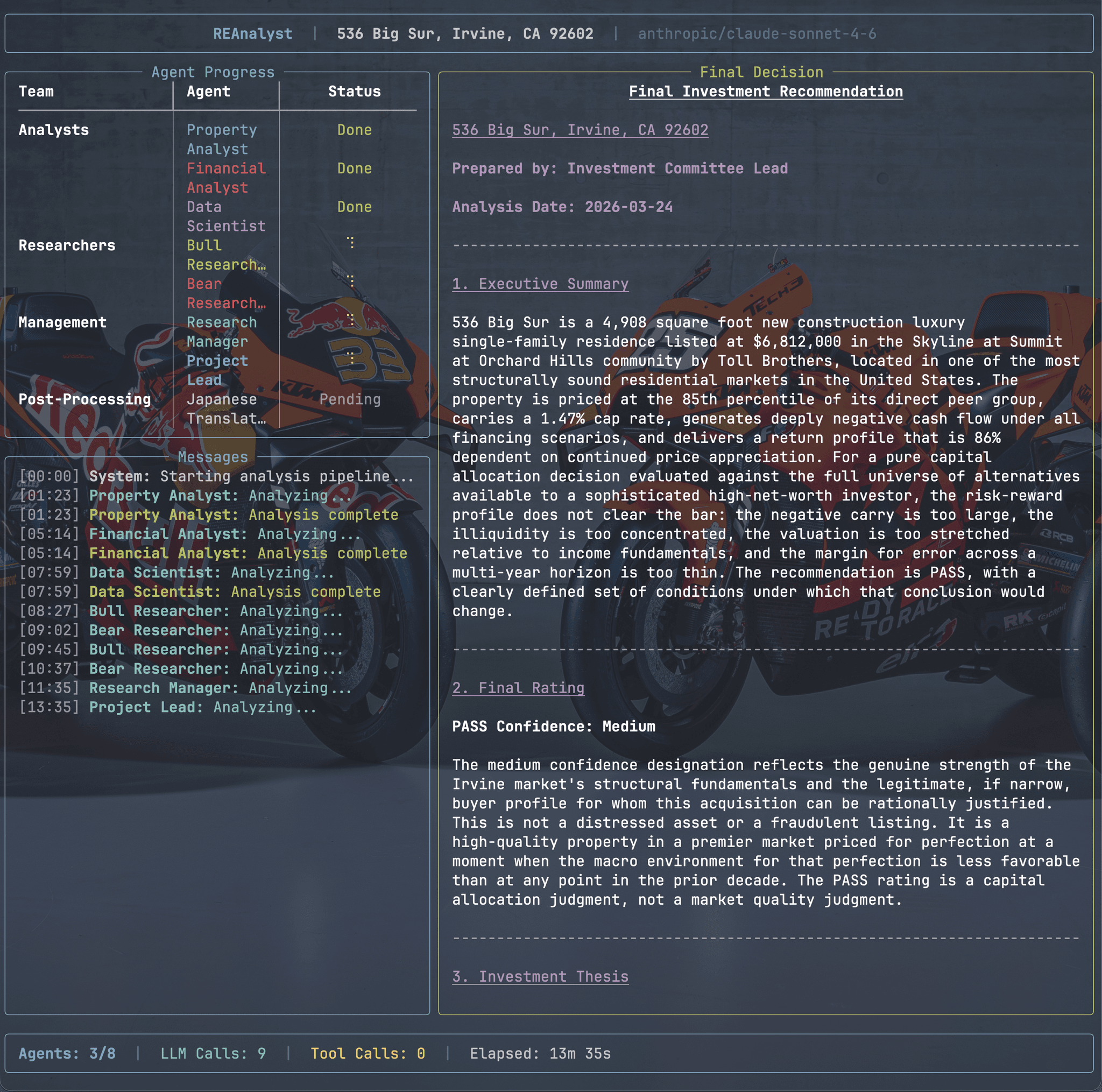
Overview
REAnalyst is a multi-agent real estate investment analysis platform. Given a property address, it runs a pipeline of specialized LLM agents — each with a distinct analytical role — to produce a comprehensive investment recommendation (Buy, Finance, or Pass) backed by financial models, market analysis, comparative metrics, and a structured bull/bear debate. The final output is a polished multi-format report package in both English and Japanese.
The system is designed for real estate investors who need thorough due diligence covering market analysis, financial projections across multiple financing scenarios and time horizons, and transparent risk assessment — all automated through a single CLI command.
Architecture
The pipeline is orchestrated with LangChain + LangGraph, modeling the analysis as a state machine where each node is a specialized agent. The state accumulates reports from each stage, and agents can read upstream outputs to build on prior analysis.
The agent pipeline flows through these stages:
- Property Analyst — gathers property details and comparable sales using tool calls to external APIs
- Financial Analyst — builds financial models with IRR projections across 3 financing scenarios and 3 time horizons (5/10/15 years)
- Data Scientist — analyzes metrics and generates chart specifications for the report
- Bull Researcher / Bear Researcher — adversarial debate loop with configurable rounds, where each side sees and counters the other’s arguments
- Research Manager — synthesizes the debate and weighs both sides
- Project Lead — produces the final Buy/Finance/Pass decision
- Japanese Translator — translates the consolidated report preserving exact structure
The system supports OpenAI, Anthropic, and Google models with automatic model resolution per provider, including extended thinking for reasoning models.
Key Features
Resume-from-Interruption Pipeline
Every agent’s output is cached to disk. If the analysis is interrupted, re-running the same command auto-detects completed steps and resumes from the first incomplete agent. Use --fresh to force a full rerun.
Multi-Source Data Integration
Property data comes from Redfin scraping (or manual input), demographics from the US Census Bureau API, economic indicators and mortgage rates from FRED, market trends from Zillow ZHVI CSVs, school ratings from Niche.com, and crime statistics from FBI data. Each source has graceful fallbacks for when APIs are unavailable.
Comprehensive Financial Modeling
Three financing scenarios (all-cash, 30-year conventional, 15-year conventional) are projected across 5, 10, and 15-year horizons. Metrics include IRR, NPV, cash-on-cash return, total appreciation, depreciation schedules, property tax burden, 1031 exchange implications, and sensitivity analysis on appreciation rates, rental income, interest rates, and vacancy rates.
Adversarial Bull/Bear Debate
Bull and Bear researcher agents argue for and against the investment over multiple configurable rounds. Each side sees the other’s arguments and can counter them. A BM25-based memory system lets the researchers reference similar past analyses to strengthen their reasoning. The Research Manager then synthesizes both perspectives into a balanced verdict.
Multi-Format Report Generation
The final consolidated report is rendered as PDF (via WeasyPrint with CSS styling), HTML (with base64-embedded charts), DOCX (with embedded images), Markdown, and an Excel workbook with property summary, financial projections, and sensitivity tables. PNG charts (bar, line, scatter, pie, grouped bar) are generated via Matplotlib.
Bilingual Output
Full English and Japanese report generation. The Japanese translator preserves exact document structure, and both languages use identical rendering pipelines. A batch translation script can also translate individual agent reports from prior runs.
Design Decisions
Message clearing between agents prevents context pollution — after each tool-using agent completes, a dedicated node extracts the final report, saves it to disk, and clears the message history before the next agent begins.
Content normalization across providers handles Anthropic’s list-of-dicts content format vs OpenAI’s plain strings, ensuring all downstream processing works uniformly regardless of which LLM provider is active.
BM25 memory stores past analyses with their decisions, allowing agents to bootstrap reasoning for new properties by referencing similar ones. Separate memory files are maintained per agent category.
Tech Stack
- Orchestration: LangChain, LangGraph (state machine agent pipeline)
- LLM Providers: OpenAI, Anthropic, Google (configurable per run)
- Data Sources: Census Bureau, FRED, Redfin, Zillow ZHVI, Niche.com, FBI Crime Data
- Analysis: Pandas, Matplotlib, OpenPyXL
- Report Generation: WeasyPrint (PDF), Jinja2, Python-DOCX
- CLI: Typer, Rich (terminal UI)
- Memory: BM25 similarity search for past analyses